2019 / 05 / 05
Web Worker 详解
Web Worker(以下简称 Worker)是 JavaScript 多线程编程的解决方案。通过创建一个 Worker,Web 页面(或称「主线程」、「宿主页面」)可以在不阻塞主线程的前提下,执行一些比较费时的任务。在这 2019 年春天,Worker 的浏览器兼容性已经相当好了,但此前我还未有机会(或必要性)在生产环境使用 Worker。前段时间,为了调研 OffScreen Canvas 的技术方案,我仔细研究了一下 Worker,不妨记录下来备忘;如果能帮助到读者,即是意外之喜了。
MessageChannel
MessageChannel(消息管道)是用来传递消息的基础类。在浏览器内部,Worker (应该是)继承了 MessageChannel 。看看 MessageChannel 怎么用:
const c = new MessageChannel();
c.port1.onmessage = e => console.log(`port_1 receive: ${e.data}`);
c.port2.onmessage = e => console.log(`port_2 receive: ${e.data}`);
c.port1.postMessage("hello from port_1");
// => port_2 receive: hello from port_1
c.port2.postMessage("hello from port_2");
// => port_1 receive: hello from port_2
如上所示,从 port1 发出的消息被 port2 监听到;反之,从 port2 发出的消息也被 port1 监听。在同一个 JavaScript 上下文中,MessageChannel 似乎没有什么存在的必要;而 MessageChannel 的妙处即在于,它可以跨越不同的 JavaScript 上下文传输消息。例如,这个例子演示了一个 iframe 中的页面是如何与它的宿主页面进行通信的。
注意,如果在发送消息时,另一个端口(port)上没有监听函数,那么 MessageChannel 会缓存消息,直到另一个端口上挂载了监听函数(此时依次收到之前缓存的所有消息)。
本文所关心的,是 JavaScript 主线程与 Worker, 以及不同 Worker 之间,如何进行通信。
Worker 基本用法
通常,需要把主线程代码和 Worker 代码分别写在两个文件中,如下所示:在主线程通过 URL(即 worker-add.js)加载 Worker 代码并创建 Worker。完成创建后,调用 postMessage 方法向 Worker 内发送一个消息,内容(或称消息体)为 JSON 对象 { a: 1, b: 2 }。然后注册监听函数,将 Worker 返回的消息中的 sum 字段打印出来。
// main.js
const worker = new Worker('worker-add.js');
worker.postMessage({ a: 1, b: 2 });
worker.onmessage = e => {
console.log(`message received: ${e.data.sum}`)
}
Worker 的 JavaScript 上下文中存在全局对象 self,它代表这个 Worker 的上下文,可以通过向 self 注册 onmessage 函数以监听外部传入的消息。这个例子在收到主线程传来的消息后,将消息体(e.data)的字段 a 和字段 b 相加,并把结果作为字段 sum 发送回主线程:
// worker-add.js
self.onmessage = e => {
const { a, b } = e.data;
self.postMessage({ sum: a + b });
};
这样,整个例子就完成了一次加法运算。主线程将加法的两个参数传入 Worker,Worker 负责进行运算并返回结果,主线程打印出 message received: 3。
如果某个时候,不再需要此 Worker 了,可以调用 worker.terminate() 强制结束 Worker。注意,Worker 中不会有机会进行清理工作。
内联 Worker(通过字符串创建)
有时,因为某些工程上的原因(或者干脆是为了省事儿),有些人也通过包含 Worker 代码的字符串来创建 Worker:将代码字符串转化为 Blob 和 URL,然后再「加载」它。而且,一个常见的实践是,利用「Function.prototype.toString() 恰好返回函数体代码」这一特性来获取包含 Worker 代码的字符串。
// 我认为不太合适的做法
function createWorker(workerFuncStr) {
const src = `(${workerFuncStr})(self);`;
const blob = new Blob([src], {type: 'application/javascript'});
const url = URL.createObjectURL(blob);
return new Worker(url);
}
const worker = createWorker(self => {
self.onmessage = e => {
const { a, b } = e.data;
self.postMessage({ sum: a + b });
};
});
我认为,在比较正式的项目中,应尽量避免使用这种创建 Worker 的方式。例子中的 createWorker 方法令人毫无防备,它容易使我们自然地认为传入的函数会被执行,函数中可访问闭包中的其他变量——可实际上,这个函数只是一段字符串。
Worker 不可避免地会存在依赖,也许 Webpack worker loader 是更好的选择。甚至,可以利用 SplitChunks 机制与 importScript 来允许 Worker 与主线程共享某些依赖。
初始化参数
创建 Worker 时,除了 Worker 代码的 URL,还可以传入一些参数:
new Worker(url, {name: "classic", credentials: "omit", name: "worker-1"})
type:Worker 的格式类型。默认为classic,标准里说还可以是module,估计是预留给浏览器原生模块方案用的。但是经过试验,就连 Chrome 也不支持module。credentials:来源合法性类型,默认是omit。目前我还不会有跨域 worker 的需求,所以没有细究。name:名称,默认为空。如果创建 Worker 时指定了名称,那么 Worker 内的上下文self上将存在相同值的name字段。此参数多少有点用处(或者便利性)吧。
Worker 的上下文
Worker 的 JavaScript 上下文与主线程的上下文是隔离的。最直白的体现是:Worker 中无法访问 DOM API,无法直接操作宿主页面。宿主页面也无法通过 postMessage 把 DOM API 传递过去。详细地1:
- Worker 中不支持的操作:
- 使用 DOM API。
- Worker 中支持的操作:
navigator和location对象(只读);XMLHttpRequest对象,用来发起请求;- 计时器相关,包括
setTimeout/clearTimeout,setInterval/clearInterval和requestAnimationFrame/cancelAnimationFrame; importScripts,引入 Worker 的依赖;Worker本身,用以在 Worker 中继续创建 Worker。
PostMessage
如果不同的线程间不能通信,那么 Worker 的意义将被大大削弱。遵循 MessageChannel 接口,Worker 使用 postMessage 方法与宿主页面或其他 Worker 进行通信。
postMessage 可以发送那些能够被 结构克隆算法(structured clone algorithm)所克隆的对象。具体地说,包括:
- 除
Symbol以外的 5 种原始类型变量:数值、字符串、布尔值、undefined、null; Map和Set对象;Date对象;RegExp对象;Blob和File对象;ArrayBuffer和ArrayBufferView(如Float32Array,Uint16Array等);ImageData对象;- 由以上类型对象组成的
Array或Object;换言之,Array中的项或Object中的属性,只能是上述类型的值或对象,一种通俗的说法是 "plain object" 或 "plain array"。
对于 Object 类型的对象,即使其内部存在环状引用,也不影响被发送。
// main.js
const o1 = {o2: null}, o2 = {o1: o1};
o1.o2 = o2;
const worker = new Worker('worker.js');
worker.postMessage(o1); // OK!
// worker.js
self.onmessage = e => {
const o1 = e.data;
console.log(o1.o2.o1 === o1); // => true
};
最重要的是,Worker 中接收到的数据对象,全部是从主线程发送的消息体中深度克隆得来的,两者虽然长得一模一样,事实上却是两个独立的实例,后续即使对其中一个对象进行修改,不会影响到另一个对象。
// worker.js
self.onmessage = e => {
const obj = e.data;
obj.val = 2;
console.log(`worker : obj.val is changed to ${obj.val}`);
self.postMessage(null);
};
// main.js
const obj = { val: 1 };
const worker = new Worker('worker.js');
worker.postMessage(obj);
worker.onmessage = e => {
console.log(`main thread : obj.val is still ${obj.val}`);
}
// output
// > worker : obj.val is changed to 2
// > main thread : obj.val is still 1
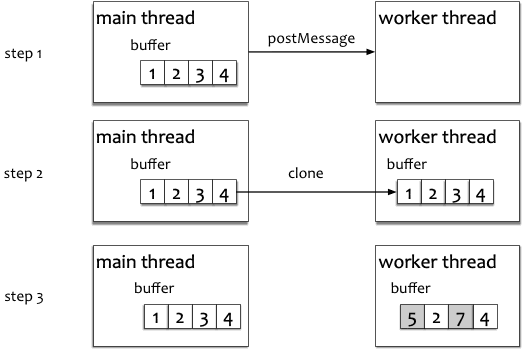
引用传递
深度克隆的好处是保护了线程的安全,付出的代价是空间和时间。一些通信发生极为频繁的场景无法承担这样的代价,此时需要以引用传递的方式来通信。浏览器中,实现了 Transferable 接口的对象可以被引用传递。具体地,包括 ArrayBuffer,MessagePort,ImageBitmap 和 OffscreenCanvas。
引用传递的本质是共享内存,即传递的是一个指针,内存数据无需发生变化。但是,为了线程安全考虑,当一段数据从源上下文传入目标上下文后,就无法在源上下文中再次访问这段内存了:
// worker.js
self.onmessage = e => {
const buffer = e.data;
const array = new Float32Array(buffer);
array[0] = 5, array[2] = 7;
self.postMessage(buffer, [buffer]);
};
// main.js
const array = new Float32Array([1, 2, 3, 4]);
const worker = new Worker('/basic-worker.js');
console.log(`before post : ${array.length} - ${array}`);
worker.postMessage(array.buffer, [array.buffer]);
console.log(`after post : ${array.length}`);
worker.onmessage = e => {
const retrArray = new Float32Array(e.data);
console.log(`after retrieval : ${retrArray.length} - ${retrArray}`)
}
// output :
// > before post : 4 - 1,2,3,4
// > after post : 0
// > after retrieval : 4 - 5,2,7,4
上面这个例子,主线程创建了类型化的 32 位浮点数组(Float32Array),其值为 [1.0,2.0,3.0,4.0]。本质上,它是一段 16 字节长的内存(ArrayBuffer),每个 32 位浮点数占 4 个字节。发送之前,我们将其打印出来:before post : 4 - 1,2,3,4。
使用 postMessage 把这段内存数据发送给 Worker:此时,postMessage 接收两个参数,形如 worker.postMessage(message, [transfer]) 。除了常规的第一个参数 message,还通过第二个参数(为一个数组) [transfer] 来指定「哪些数据需要传递引用」这一信息。若不在 [transfer] 中指定,那么这个 buffer 就会像普通的数据那样进行深度克隆。比如,worker.postMessage({b1: buffer1, b2: buffer2}, [buffer2]); 就会对 buffer1 进行深度克隆,而对 buffer2 进行引用传递。
为了线程安全,当一段内存数据被以引用传递的方式发送出去后,在当前上下文就无法再访问了。对类型化数组如 Float32Array 而言,具体的表现是,它会成为一个去势(neutered)的数组(可以理解为成了一个空壳),其长度为 0,此时打印数组的结果是 after post : 0(尝试访问/打印元素将导致抛出异常)。
Worker 线程拿到这段内存,并按照 Float32Array 的格式来解析它。接着,改写其中的值,把第 1 个和第 3 个元素改成 5 和 7,最后同样以引用传递的形式把它发回给主线程。
主线程拿回了这段内存,按照 Float32Array 重新解析这段内存(可以理解给内存套壳,开销很低;注意,之前的壳是不能复用的,需要重新套壳),并将解析得到的数组打印出来,结果是 after retrieval : 4 - 5,2,7,4。可见,数据被 Worker 线程篡改了。
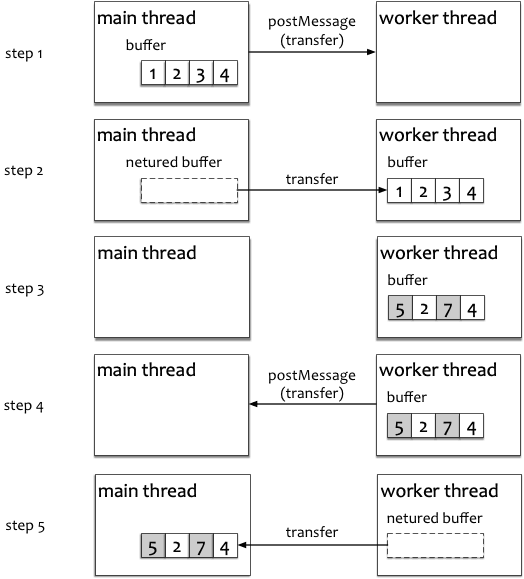
多 Worker 间通信
不仅主线程和 Worker 线程间可以通信,不同的 Worker 之间也可以通信,这是通过 MessageChannel 实现的。MessageChannel 对象上存在两个 成员属性:port1 和 port2,它们均是 MessagePort 对象。MessagePort 也实现了 Transferable 接口,我们可以像传递 ArrayBuffer 那样把 MessagePort 传入 Worker 中:
// worker1.js
let port;
const handleInit = (data) => {
port = data.port;
};
const handleTransfer = (data) => {
port && port.postMessage({
type: 'TRANSFER',
message: data.message + ' through worker1;'
})
};
self.onmessage = function (e) {
const handleMessage = e.data.type === 'INIT' ?
handleInit : handleTransfer;
handleMessage(e.data);
}
// worker2.js
self.onmessage = function (e) {
const port = e.data.port;
port.onmessage = function (e) {
self.postMessage({
type: 'TRANSFER',
message: e.data.message + ' through worker2.'
});
}
}
// main.js
const worker1 = new Worker("worker1.js");
const worker2 = new Worker("worker2.js");
const channel = new MessageChannel();
worker1.postMessage({ type: 'INIT', port: channel.port1 }, [channel.port1]);
worker2.postMessage({ type: 'INIT', port: channel.port2 }, [channel.port2]);
worker1.postMessage({ type: 'TRANSFER', message: "Hello from main thread;" });
worker2.onmessage = function (e) {
console.log(e.data.message);
}
// output
// > Hello from main thread; through worker1; through worker2.
上面的例子中,主线程创建了两个 Worker:worker1 和 worker2;然后,创建了 MessageChannel 对象,并将它的 port1 和 port2 分别传递给 worker1 和 worker2。
接着,主线程把将字符串 "Hello from main thread;" 发送给 worker1;worker1 收到此字符串后,加上了 " through worker1;",并(通过之前传过去的 port1)发送给 worker2;worker2 在收到(从之前传过去的 port2 中监听到)此字符串后,又添加上 " through worker2.",最后发送给主线程。我们在主线程中打印出最后得到的消息字符串,为 "Hello from main thread; through worker1; through worker2."。
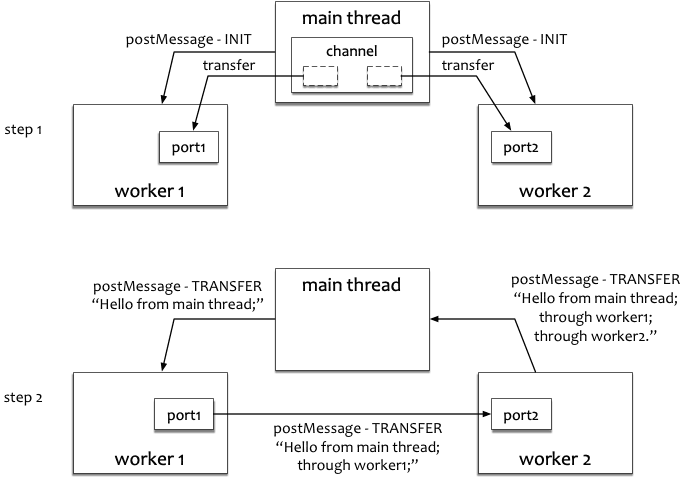
MessagePort 只能被通过传递引用的方式发送到 Worker 中。与 ArrayBuffer 类似,其被传递到另一个 JavaScript 上下文之后,留在原上下文中的对象便成了空壳,试图调用其上的 postMessage 方法将导致抛出异常。
在 Worker 线程中绘图
Offscreen Canvas 的出现使得在 Worker 中进行绘图成为可能。由于 OffScreenCanvas 也实现了 Transferable 接口,主线程能够将 OffScreenCanvas 的引用传递至 Worker 线程。同样,当 offscreenCanvas 被传递到 Worker 中后,留在主线程里的对象便成了空壳,试图调用其上的任何方法都将导致抛出异常。
// worker.js
self.onmessage = e => {
const canvas = e.data;
const ctx = canvas.getContext('2d');
ctx.fillStyle = '#FF0000';
ctx.fillRect(0, 0, canvas.width, canvas.height);
}
// main.js
const canvas = document.querySelector('canvas');
const offscreenCanvas = canvas.transferControlToOffscreen();
const worker = new Worker('canvas-worker.js');
worker.postMessage(offscreenCanvas, [offscreenCanvas]);
OffScreen(离屏)Canvas 可以被直接创建,也可从普通 Canvas 中创建而来,它的用法不是本文的重点。
上面这个例子把页面上一个普通的 Canvas 的控制权转交给了离屏 Canvas,然后将离屏 Canvas 以引用传递的方式发送给 Worker。然后,在 Worker 中进行绘制操作,为 Canvas 区域涂满红色。
图片加载
绘图,自然涉及图片资源的加载。传统方式是通过 Image 对象来加载图片以及绘图。然而,Worker 中不存在 Image 对象(也许是因为 Image 过于上层,与 DOM 的关联之处过多),这就需要一种更新、更接近底层的方法来加载图片:通过 fetch 方法直接获取二进制(即 Blob 对象)的图片数据,并转化为 ImageBitmap 对象用以绘图。
// worker.js
self.onmessage = e => {
const canvas = e.data;
const ctx = canvas.getContext('2d');
fetch(yourUrl,).then(response => response.blob())
.then(blob => createImageBitmap(blob))
.then(bitmap => ctx.drawImage(bitmap, 0, 0));
}
ImageBitmap 是 Image 或 HTMLImageElement 背后的某种存在,或者说是去除了 DOM 功能(如 onload、style 等等)后的 Image ,表示存储 Image 中像素数据的那一块内存区域。在 Canvas 相关的操作中,大部分涉及到 Image 的方法,在接收 Image 参数的时候,也接收 ImageBitmap 对象。如 CanvasRenderingContext2D#drawImage 或 WebGLRenderingContext/texImage2D。同样,ImageBitmap 作为一块内存区域,也可以被以引用传递的方式在 Worker 和主线程间传递。如果绘图操作逻辑需要进一步细粒度的拆分,也许可以利用这一特性来交换绘图过程中产生的中间结果。
注意:OffScreenCanvas 的浏览器兼容性比 Worker 要差很多。
小结
以上即是我对 Web Worker 相关技术进行调研的梳理和总结,记录下来备忘。