2012 / 09 / 12
模型视图投影矩阵
最近在学习 WebGL 技术的过程中,我补充了一些原本了解甚少的计算机图形学知识,模型视图投影矩阵就是其中之一。
模型视图投影矩阵的作用,就是将顶点从局部坐标系转化到规范立方体(Canonical View Volnme)中。总而言之,模型视图投影矩阵=投影矩阵×视图矩阵×模型矩阵,模型矩阵将顶点从局部坐标系转化到世界坐标系中,视图矩阵将顶点从世界坐标系转化到视图坐标系下,而投影矩阵将顶点从视图坐标系转化到规范立方体中。
如下图所示,假设现在要将三维空间中的三角形渲染到屏幕上。三角形的模型文件中,顶点坐标是在局部坐标系(Xl-Yl-Zl)下的,比如图中三角形三个顶点的初始坐标就可能是(1,0,0),(0,1,0),(0,0,1)。
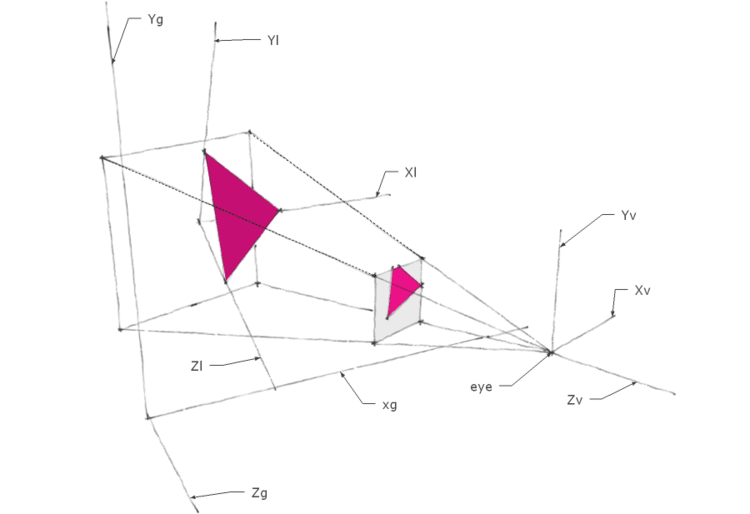
模型矩阵
模型矩阵将局部坐标系下的顶点坐标转化到世界坐标系下。此处就要涉及局部坐标系相对于世界坐标系的位置和方向,或者说空间中的点的位置发生变化时,坐标如何变化。
考虑三种基本的变换:平移、旋转和缩放。
「变换」的含义就是,将点的初始位置的坐标P映射到平移、旋转、缩放后的位置坐标P’,即:
平移变换是最简单的变换:
旋转变换有一些复杂,先看在二维平面上的旋转变换:
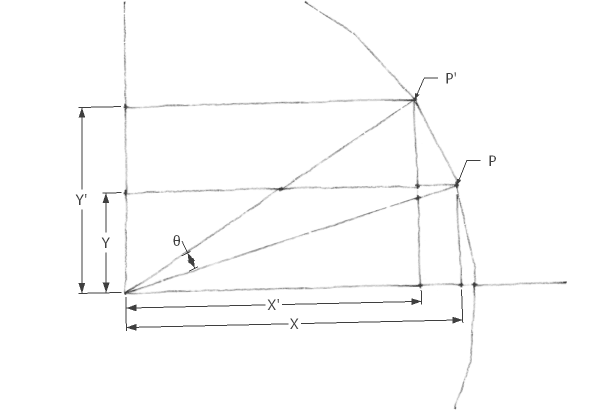
很容易得到:
矩阵形式的表达更加简洁:
推广到三维空间中:
点绕Z轴旋转:
点绕X轴旋转:
点绕Y轴旋转:
绕指定的任意轴旋转变换是由几个绕坐标轴旋转变换和平移变换效果叠加而成。
缩放变换也比较简单:
总结一下:平移变换,变换后点坐标等于初始位置点坐标加上一个平移向量;而旋转变换和缩放变换,变换后点坐标等于初始位置点坐标乘以一个变换矩阵。
齐次坐标这天才的发明,允许平移变换也表示成初始位置点坐标左乘一个变换矩阵的形式。齐次坐标使用4个分量来表示三维空间中的点,前三个分量和普通坐标一样,第四个分量为1。
平移变换巧妙地表示为:
旋转变换(以绕z轴旋转为例)和缩放变换相应为:
综上,在齐次坐标下三种基本变换实现了形式上的统一,这种形式的统一意义重大。
矩阵有一个性质:
考虑一个点,先进行了一次平移变换,又进行了一次旋转变换,结合上面矩阵的性质,可知变换后的点P’为:
旋转矩阵和平移矩阵的乘积R·T也是一个4×4的矩阵,这个矩阵代表了一次平移变换和一次旋转变换效果的叠加;如果局部坐标系还要继续变换,只要将新的变换矩阵按照顺序左乘这个矩阵,得到的新矩阵能够表示之前所有变换效果的叠加,这个矩阵称为「模型矩阵」。
模型矩阵之所以称之为「模型矩阵」,是因为一个模型里所有的顶点往往共享同一个变换,如抛在空中的一个木块,运转机器中的一个齿轮。
考虑一个物体绕任意的轴(而不是三个坐标轴)旋转,如:绕着过顶点(x, y, z)的方向为(a, b, c)的轴,旋转角度θ。这时可用多个变换的叠加构建矩阵: 首先将顶点(x, y, z)平移到原点,绕X轴旋转角度p使指定的旋转轴在x-z平面上,绕Y轴旋转角度q使指定的旋转轴与Z轴重合,绕指定旋转轴(也就是z轴)旋转角度θ,绕Y轴旋转角度-q,绕X轴旋转角度-p,将顶点平移到向量(x,y,z)。p和q的值可以通过(a,b,c)计算出来。综上,变换矩阵为:
齐次坐标还有一个优点,能够区分点和向量:在普通坐标里,点和向量都是由三个分量组成的,表示位置的点坐标(x, y, z)和表示方向的向量(x, y, z)没有区别。而在齐次坐标中,表示位置的点坐标为(x, y, z, 1),而表示方向的向量为(x, y, z, 0)。平移一个点能够得到平移后的点坐标;而平移一个向量什么都不会发生。比如:
来看个具体的例子:一个绕z轴匀速螺旋匀速上升的立方体,在某一帧中(即在这一帧对应的时刻t下),其向z轴正方向平移的长度和绕z轴旋转的角度分别为:
则模型矩阵(注意上文齐次坐标下的基本变换矩阵)为:
产生这一帧时,只需要计算一次模型矩阵,再将立方体中8个顶点坐标分别左乘该矩阵,就可以得到经过变换后8个顶点的坐标。当一个模型顶点数量增加到上百甚至上千个,模型变换的步骤数也增加到几十步时,模型矩阵的作用就很明显了:如果没有齐次坐标(也当然没有模型矩阵),对每个顶点都需要一步一步地变换:平移的时候加上一个向量,旋转的时候左乘一个矩阵,才能得到变换后的顶点坐标;而模型变换只需要计算一次模型矩阵(当然也是一步一步的),然后每个顶点左乘模型矩阵就可以直接得到变换后的坐标了。
视图矩阵
相比点的世界坐标,我们更关心点相对于观察者的位置(视图坐标)。如果观察者置于原点处,面向Z轴负半轴,那么点的世界坐标就是其试图坐标。观察者的位置和方向会变化,看上去就好像整个世界的位置和方向发生变化了一样,所以我们将世界里的所有模型看作一个大模型,在所有模型矩阵的左侧再乘以一个表示整个世界变换的模型矩阵,就可以了。这个表示整个世界变换的矩阵又称为「视图矩阵」,因为他们经常一起工作,所以将视图矩阵乘以模型矩阵得到的矩阵称为「模型视图矩阵」。模型视图矩阵的作用是:乘以一个点坐标,获得一个新的点坐标,获得的点坐标表示点在世界里变换,观察者也变换后,点相对于观察者的位置。
如果将观察者视为一个模型,那么视图矩阵就是观察者的模型矩阵的逆矩阵。
观察者平移了(tx, ty, tz),相当于整个世界平移了(-tx, -ty, -tz)。
观察者绕Z轴旋转了角度θ,相当于整个世界绕Z轴旋转了-θ度。
观察者在三个方向等比例缩小了s倍,相当于整个世界等比例放大了s倍。
观察者缩小的情形曾经使我困惑:
一方面,即使人和猫咪的眼睛在同一个位置,人看到的世界和猫咪看到的世界应当是一样尺寸的(虽然人比猫大);但是直觉告诉我,如果你喝了变猫药水,你应该会觉得整个世界在膨胀,就像视图矩阵所表现的那样。解答是这样:如果在计算机上模拟观察者喝了缩小药水的情形,在屏幕上看到整个世界是膨胀的,因为在那个虚拟的三维空间中,计算机屏幕这个「窗口」也随你(观察者)缩小。
视图矩阵实际上就是整个世界的模型矩阵,这给我一点启发:一个模型可能由多个较小的子模型组成,模型自身有其模型矩阵,而子模型也有自己的局部模型矩阵。考虑一辆行驶中的汽车的轮胎,其模型视图矩阵是局部模型矩阵(描述轮胎的旋转)左乘汽车的模型矩阵(描述汽车的行驶)再左乘视图矩阵得到的。
投影矩阵
投影矩阵将视图坐标系中的顶点转化到平面上。
实际上,投影矩阵先把顶点坐标转化到规范立方体坐标系(Xc-Yc-Zc)中,也就是将四棱锥台体空间映射到规范立方体中。规范立方体是x,y,z都处在区间[-1,1]之间的边长为2的立方体,如下所示。顶点在其中的坐标,其x值和y值直接就是顶点在屏幕上的坐标,而z坐标值可以用来表示顶点深度,如果两个不同顶点投影到平面上时重合了,深度可以来确定那个点在前面。
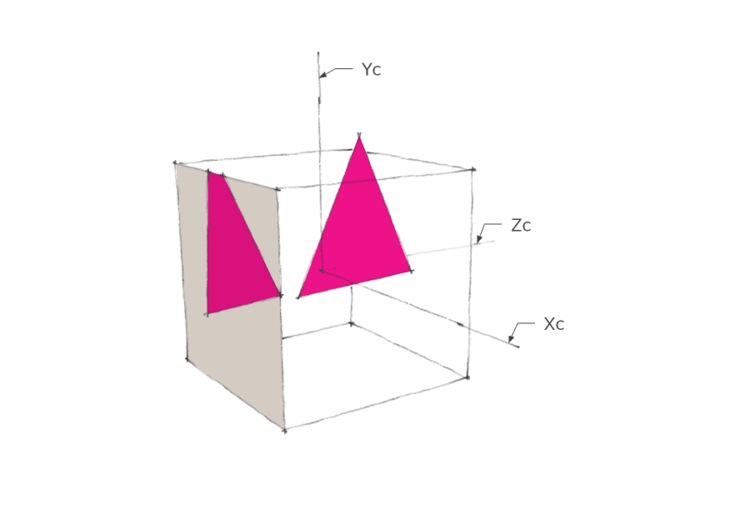
屏幕模拟了一个窗口,你透过这个窗口观察「外面」的世界。你的屏幕是有边缘的,因此你仅仅能观察到世界的一部分,即「相机空间」。相机空间的左、右、上、下边界是受限于屏幕的边缘,同时也设定前、后边界,因为你很难看清太近或太远的东西。相机空间就是上述的四棱锥台体。
主要的有两种投影方式,正射投影和透视投影。前者用于精确制图,如工业零件侧视图或建筑物顶视图,从屏幕上就可以量测平行于屏幕的线段长度;后者用于模拟视觉,远处的物体看上去较小。这里只讨论透视投影,正射投影是类似的。
显然,投影矩阵取决于相机空间的参数。令相机空间的最近处与观察者的距离为near,而最远处与观察者距离为far,屏幕宽高比为aspect,水平视角为fov,通过原理简单和略微繁杂的计算(涉及三角函数和相似三角形),就可以求出投影矩阵:
注意,规范立方体是左手坐标系的,所以上述矩阵的第3行第3列中会出现负号。
最后,根据投影矩阵×视图矩阵×模型矩阵求出模型视图投影矩阵,顶点坐标乘以该矩阵就直接获得其在规范立方体中的坐标了。这个矩阵通常作为一个整体出现在着色器中。
(完)