2020 / 12 / 29
钉钉表格,从零到一在线 Excel —— 2020 D2 论坛演讲(全文)
以下是 2020 年 12 月 19 日在 D2 前端技术论坛上的分享全文。

大家好,我是来自钉钉的叶斋。感谢 D2 组委会,让我有机会在这里分享。我今天分享的主题是《钉钉表格 —— 从零到一打造在线 Excel》。

我们知道 Excel 是一款有着 30 年悠久历史,功能极为繁多复杂的桌面办公软件。
近十年来,随着浏览器的进化,在 Web 端出现了一些对标 Excel 的产品,比如 Google Sheets,微软自家的 O365等等。钉钉表格也是其中之一。
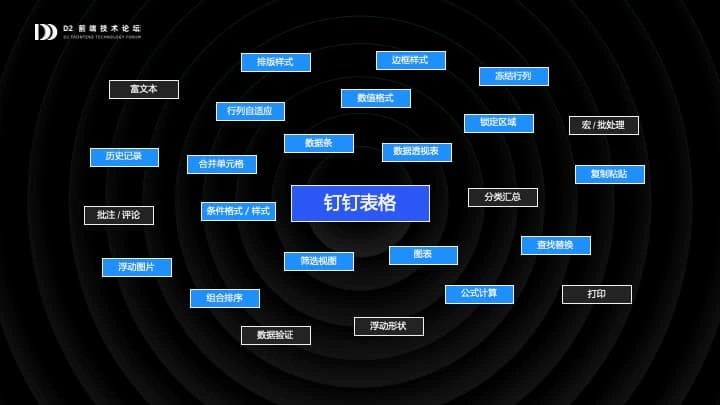
这款产品经过了接近一年的从 0 到 1 的研发,已经完成了 Excel 70% 的功能点,即将正式推出。这次的分享,我将从前端的视角,来谈谈研发这款产品中遇到的一些技术挑战,以及我们的应对策略。
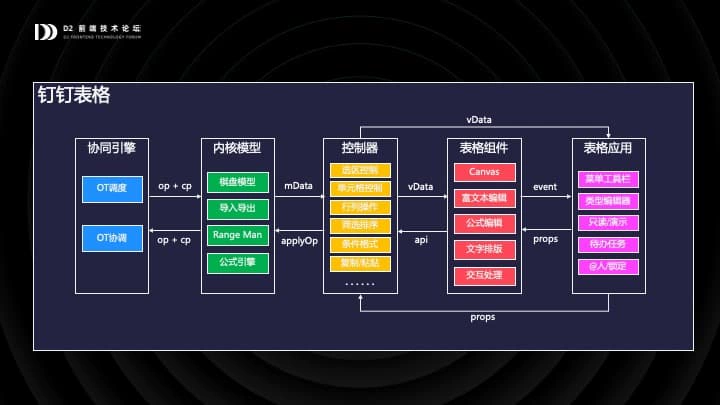
首先简单地看一下钉钉表格的模块组成,大体上分为五个部分:
- 协同引擎,负责与服务器交换数据,保证多人能够在一张表格上工作。
- 内核模型,可以理解为表格的本地数据库,提供高性能、正交的数据增删改查。
- 控制器,可以理解为 service 层,大部分表格的业务逻辑发生在这里。
- 表格组件,一个 React 组件,不包含菜单,工具栏,最主要的部分是由 Canvas 渲染的表格主界面。
- 表格应用,最终用户看到的那个钉钉表格。

接下来我带给大家三个故事:可扩展的表格、协同的表格、高性能的表格。希望能通过这三个故事,带大家一窥究竟。

第一个故事是,「可扩展的表格」。

表格最基础,最重要的数据模型,我们称之为「棋盘模型」。棋盘由行和列组成,行列的交点,就形成了一个单元格。非常简单,直观。通常,这个棋盘是由四叉树来实现的,但这里为了不过多展开,我们可以将其视为一个二维数组。
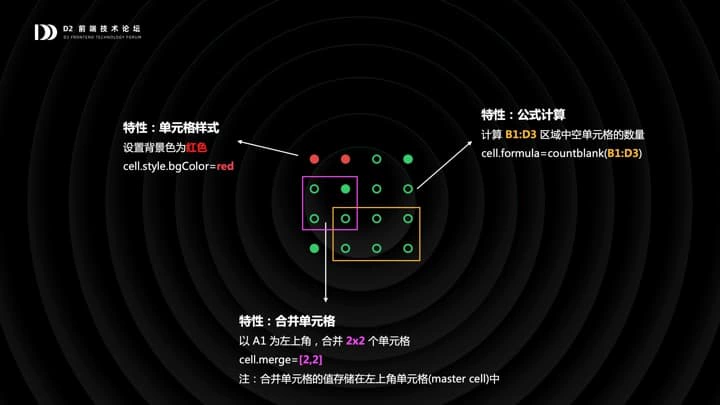
接下来的问题是:如果我想要为单元格增加样式,比如我想设置单元格的背景色为红色,这时候该对棋盘模型做什么?
一个自然的想法是,直接扩展棋盘中的单元格 cell,为其增加 style.background 属性;同理,我们可能设置单元格的值由公式计算而来,会自然想到在 cell 上增加 formula 属性;我们可能设置合并单元格,会在 cell 上增加 merge 属性,等等。
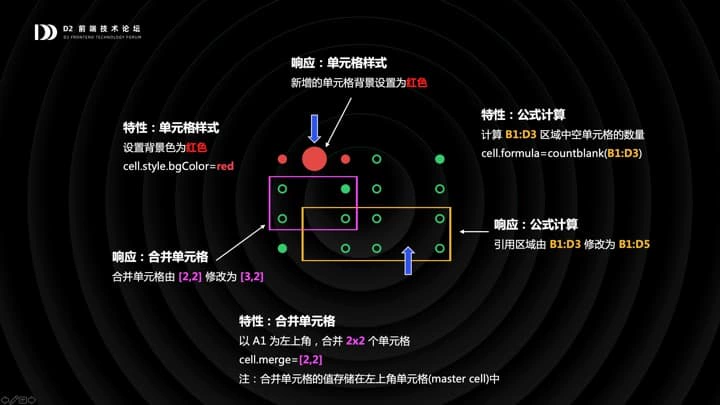
接下来,请大家想一下,如果这时用户在表格中插入了两个新列,我们需要做什么?我们需要把两个红色单元格中间新插入的那个单元格设置为红色,因为当插入的单元格两侧具有同样样式的时候,我们需要继承它;同理我们也需要更新公式引用区域的范围;还需要更新合并单元格的尺寸。
大家看,这太麻烦了,不管你增加了什么特性,都得去响应行列操作。因为行列操作在棋盘模型中,是第一公民。你们觉得应该怎么解决这个问题?
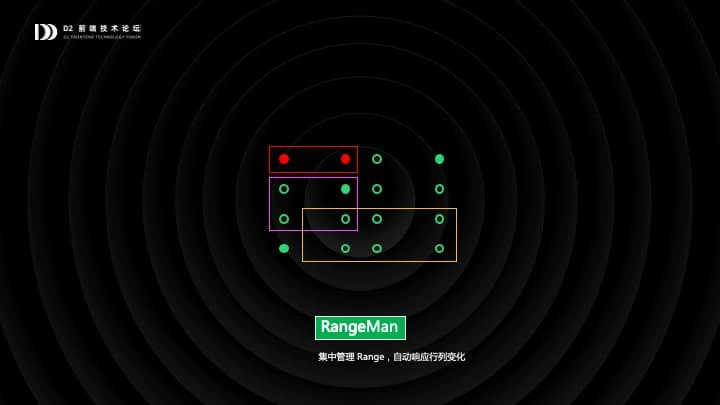
我们仔细观察一下,就会发现不管是样式,公式还是合并单元格,都不是基于单元格组织的,他们本质上是基于棋盘中的一个矩形区域来组织的,这个矩形区域这是 Range。
通过借鉴一些已有的成熟设计,我们引入了一个名为 RangeMan 模块,统一管理和维护 Range。
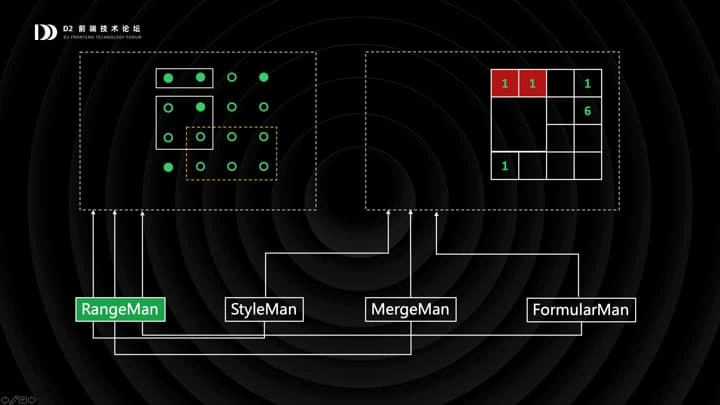
不同的功能模块通过 RangeMan 向棋盘模型注入 Range,比如当用户选中两个相邻单元格并设置样式时,其实是为一个 Range 设置了样式;公式与合并单元格也是类似的。
RangeMan 维护的数据,棋盘模型是完全感知不到的。只不过消费数据的时候,会把棋盘和各功能模块的数据组装并渲染。
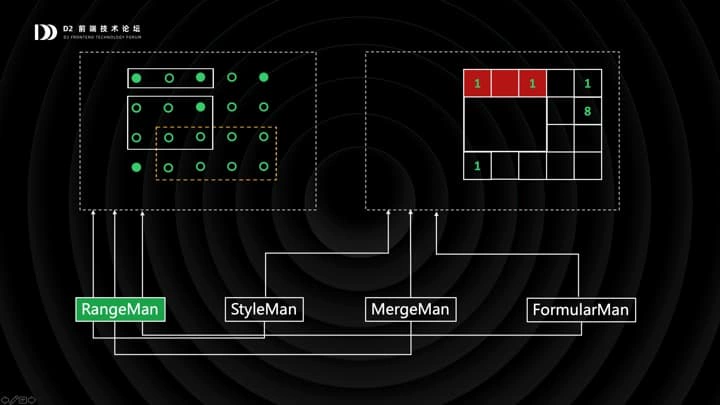
然后重点来了:当行列发生增删时,RangeMan 会自动地更新:包括可能改变 Range 的位置和尺寸,甚至删除一些 Range。然后,消费端在渲染时,从各模块获取新的 Range 并体现在界面上。这就是 RangeMan 的原理。
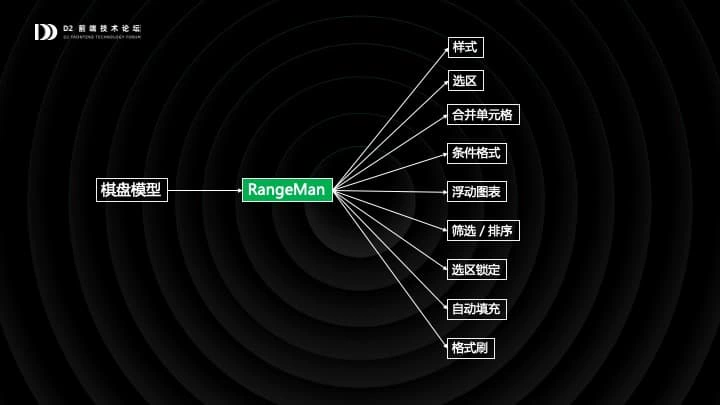
RangeMan 即简单又强大,它是表格的核心逻辑和业务逻辑间的一道屏障,把两者彻底解耦。绝大部分表格的「业务功能」,包括筛选排序、条件格式等等等等,都是在 RangeMan 的基础上扩展而来的。

这样,我们的第一个故事,可扩展的模块就讲完了。总结一下:
- 首先,棋盘模型是核心,行列操作是第一公民。
- 然后,引入 RangeMan 统一管理 Range:注册、更新、销毁。
- 最后,基于 RangeMan 扩展表格的各个功能模块。

第二个故事,是协同的表格。所谓协同,是指我们的表格支持多个用户在同一张表格上工作。
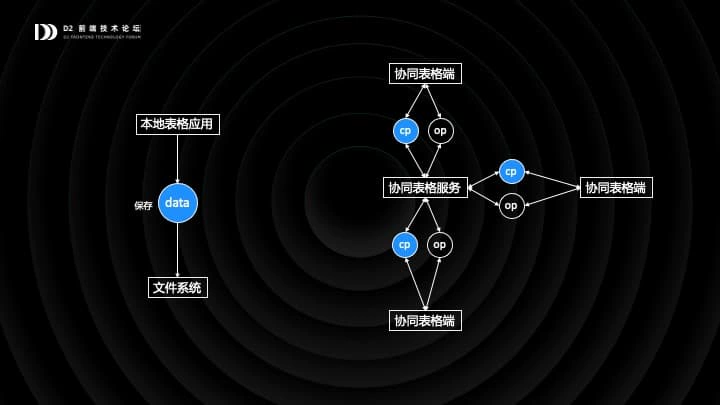
传统的桌面表格软件是不支持协同的,它的模式非常简单:用户点击「保存」按钮,软件将表格数据写入磁盘。协同表格则要复杂得多,多个用户同时通过 CP 和 OP 与服务端进行数据交换。

这里的 CP 是 Check Point 的简称,指的是全量的表格数据;OP 是 Operation 的简称,指的是单次表格操作。
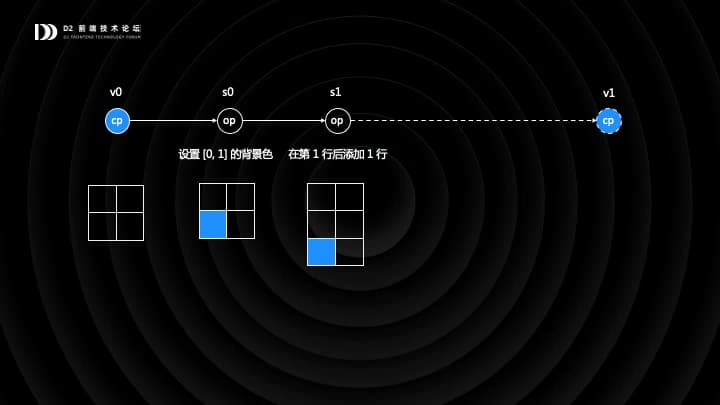
举个例子,当我们新建一个表格时,表格里什么都没有,这是一个空的 CP,版本是 v0。设置 [0,1] 单元格背景色就是一个 OP,版本是 s0。当 CP v0 执行了 OP s0,表格对应的状态,[0,1] 格就被染色了。我们可以接着执行一个 OP s1,在第一行后插入一行,表格状态也会发生变化。当积累的 OP 足够多(我们现在是每 50 个),或者用户手动保存了,或者用户一段时间没操作,我们会生成一个新的 CP,后面的 OP 就在新 CP 上累加了。
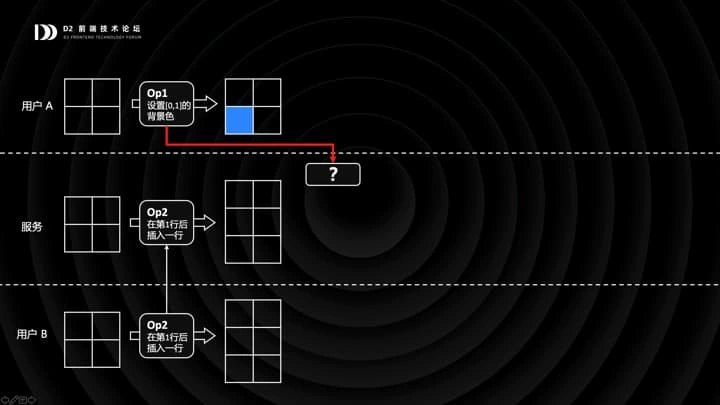
OP 和 CP 的存在,是为了多人协同。具体协同是怎样做的呢?我再举个例子,假设现在有 A / B 两个用户,同时编辑一张空表格。A 作出了一个操作 OP1,设置 [0,1] 的背景色;B 作出了一个操作 OP2,在第一行后插入一行。由于 B 的网络比较好,OP2 先同步到了服务端,服务端执行了 OP2;这时候 A 的 OP1 也同步过来了,我想请大家思考下,你会怎么办?
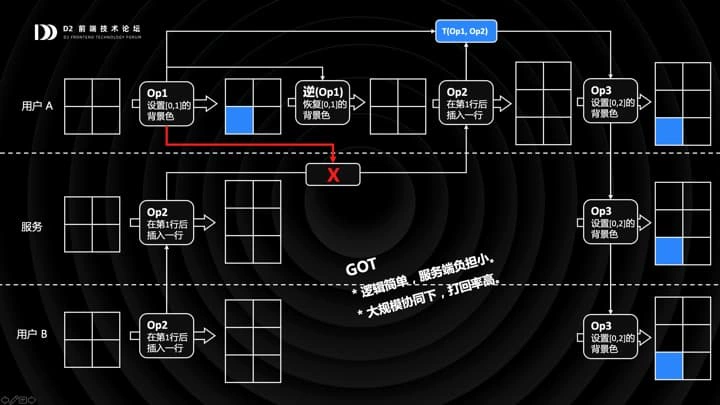
一个做法是,直接打回,告诉 A 你这个 OP 已经过时了。这时 A 会生成一个逆 OP1,恢复 [0,1] 的背景色。同时服务端会把 OP2 同步给 A,接着 A 会执行 OP2。然后,关键的一步来了:A 会基于 OP2 变换 OP1,也就是基于「在第一行后插入一行」这么一个 OP,去变换「设置 [0,1] 的背景色」这个 OP,得到新的 OP3,是设置 [0,2] 的背景色,然后再执行。当然,OP3 会依次同步给服务端和 B。
这个算法叫做 GOT,好处是逻辑比较简单,但是有一个问题,在大规模密集协同下,打回率很高,OP 密集到一定程度时,可能一个网络稍微差一点的客户端,就一直在处理打回的 OP,无法收敛。
接下来,我们介绍另一种算法:还会到刚刚的位置,当 A 的 OP1 同步到服务端时,有没有什么更好的做法?
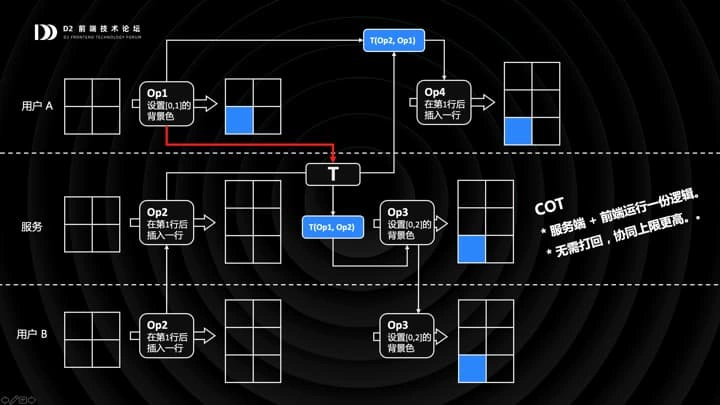
更好的做法就是:在服务端直接做变换,基于 OP2 变换 OP1,生成 OP3(也就是设置 [0,2] 的背景色),同时同步给 B。在客户端 A 呢,基于 OP1 变换 OP2,注意这里反过来了,我们基于设置背景色操作,去变换插入行操作。由于设置背景色对插入行操作是完全无影响的,所以得到的 OP4 依然是「在第一行后插入一行」,和 OP2 是完全等价的。A 执行 OP4,得到最终的结果。
这个算法叫做 COT,它的上限更高,但是代价就是需要服务端和前端同时运行一份 OP 变换的逻辑。
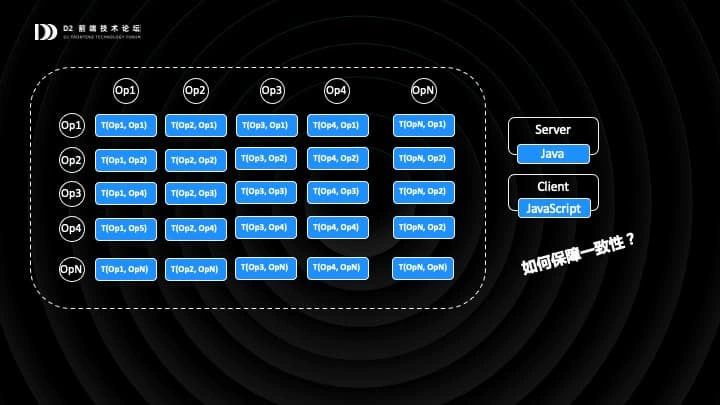
我想再问大家一个问题,协同算法里最重要的部分是什么?其实最重要的,就是图里蓝色的「OP 变换」,Operation Transformation,简称 OT。GOT 只在客户端运行 OT,而 COT 则要求在服务端和客户端同时运行 OT。
在这个例子里面,我们只有 2 种 OP,那么其实是有 4 种 OT 算法。这是一个大的 switch case,每两种 OP 碰到一起,如何变换,都是需要通过硬编码来实现的。随着 OP 的种类越来越多(比如目前表格已经有 15 种 OP 了),OT 算法的规模会以平方级增长。运行在服务端的 OT 由 Java 同学实现,前端 OT 则由前端技术栈实现,如何保障一致性呢?
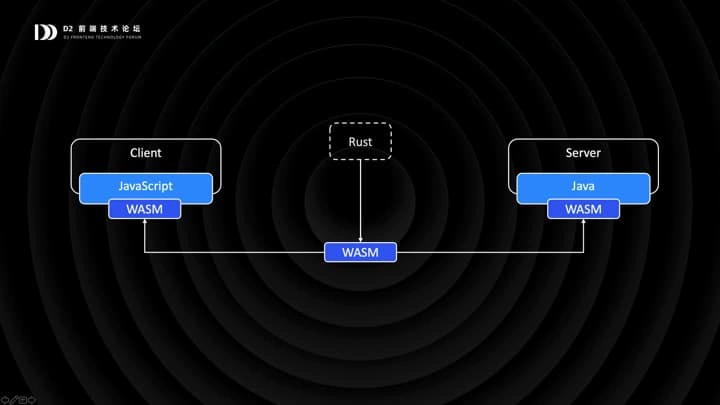
WebAssembly,对,就是 WebAssembly。总之,我们用Rust来编写OT 算法,然后编译成 Assembly,同时分发给服务端和客户端,这样就保证了双端的一致。产品迭代过程中,如果产生了新类型的 OP,也只需要在 Rust 中单独实现,重新编译和分发。

这样,第二个故事,协同的表格,就讲完了。总结一下:
- 首先,OT 是协同的关键。
- 上限更高的 COT 调度需要 OT 同时运行在服务端和前端。
- 使用 Rust + WSAM 编码 OT 算法,保障一致性。

最后一个故事是,高性能的表格。

高性能是什么?我的理解是:长时间,高强度使用,用户感觉不到卡顿。而浏览器里的卡顿,通常和渲染相关。我们知道 DOM 是渲染 Web 应用的首选方案,但是最终我们决定使用 Canvas 来渲染表格的主界面。大家知道为什么吗?
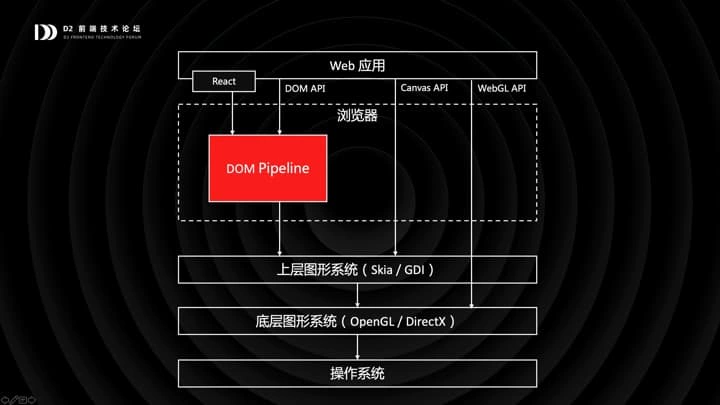
因为表格和普通网页的形式存在很大的差别,很多 DOM 模型支持的能力,表格是用不到的。这意味着,如果你用 DOM 来渲染表格,就会有很多开销不可避免地浪费在浏览器中的 DOM 渲染管线中。几十年来 DOM 标准的不断迭代,使得浏览器的 DOM 渲染管线成了一个极复杂,兼容性极强的模块,支持从内联 <b> 元素到 float 布局等诸多古老特性。这些东西,表格是完全用不上的。
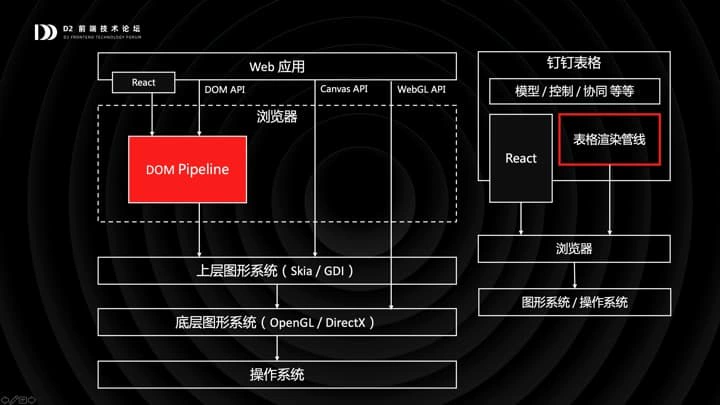
所以我们使用 Canvas,我们内部有一个「表格渲染管线」,基于 Canvas 实现。我们来看看管线内部的结构。
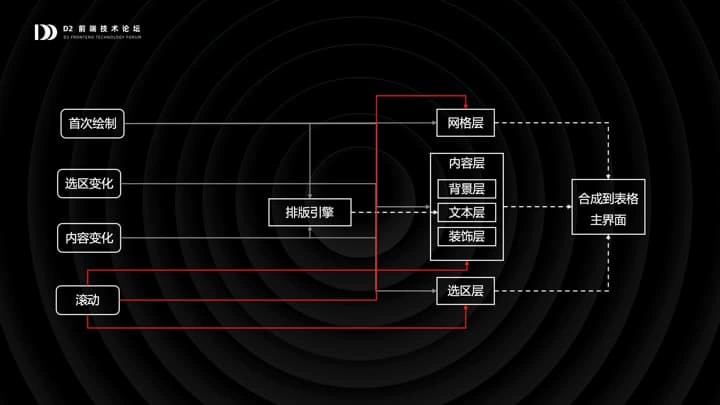
首先管线内部是分层的,首先分为网格层,内容层和选区层,内容层内又分背景、文本、装饰三层,文本层前面是排版引擎。每一层可以单独渲染,然后再合成起来,输出到主界面。虚线是管线中流淌的数据流,马上出现的实线是控制流。
- 首次渲染,需要重新排版,三层中的每一层都需要重新绘制。
- 用户拖拽选区时,只有选区层需要重绘,因为选区的渲染很简单,此时开销是很小的。
- 当用户改了单元格的值,需要重新排版(当然是增量的),内容层需要重绘。
- 表格滚动的时候,每一层都需要重绘;但不需要重新排版。
可以看到,渲染管线在发生不同的操作时,只重绘那些必要的图层,以此来保障性能。
其实分层是任何渲染系统作性能优化时的一个最基本的手段。即使分层了,我们这个表格在滚动时的重绘开销依旧比较客观。因为单元格的数量是比较多的,每个格子里面的文本有可能是换行的,甚至还有富文本出现,导致绘制文本的次数非常多。
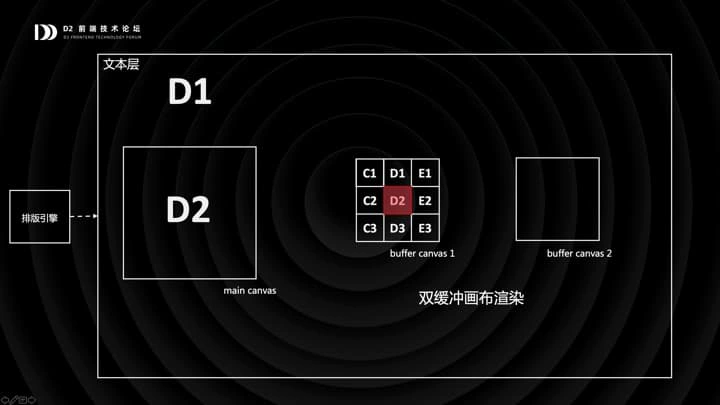
所以我们对文本层又专门作了优化:就是「双缓冲画布」的渲染方案。
我们会准备两块缓冲画布,每一块都比视窗要大一圈,视窗里的内容,比如现在的 D2 区域,是从缓冲画布中裁剪出来的。
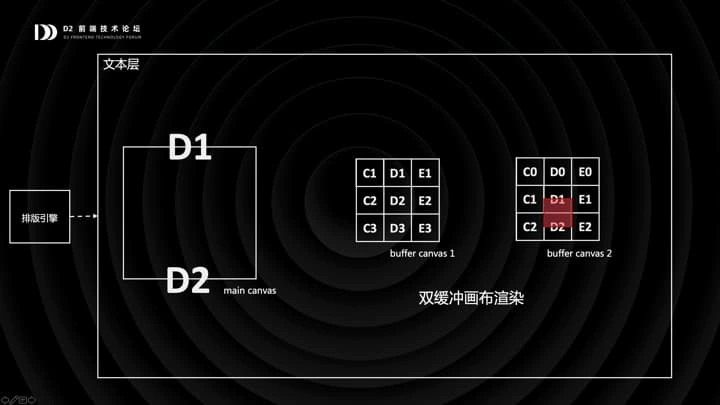
如果这时候发生了滚动,视窗从 D2 区域缓缓向 D1 滚动,我们不需要重绘,只需要从缓冲画布中裁剪新的区域过来就可以。
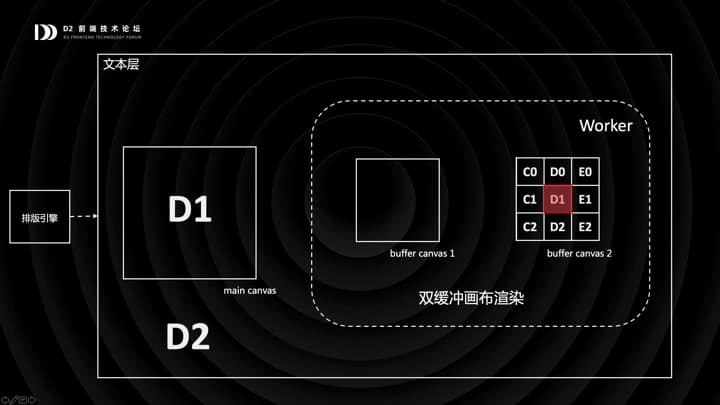
当滚动到一个阈值时,我们会在缓冲画布 2 上以 D1 区域为中心进行重绘,然后把视窗从缓冲画布 1 挪到缓冲画布 2,再清空第一块画布,这样就恢复到了初始状态,完成了一个循环。
双缓冲画布的优势是,重绘的频率大大降低了,但单次重绘的开销却变大了。所以我们在有条件的浏览器中,把缓冲画布的渲染封到 web-worker 里,这样就比较好了。
在表格渲染管线中,我们还遇到一个挑战,就是如何去对文本作排版。在 DOM 中,排版是浏览器替我们完成的:你在 div 里放一段文本,设置好 div 的宽度,浏览器会自动去折行,去对齐。使用 Canvas 之后,你就得自己手动做这件事了。我们表格内有一个小型的排版引擎,还挺有意思的,不妨也分享一下。
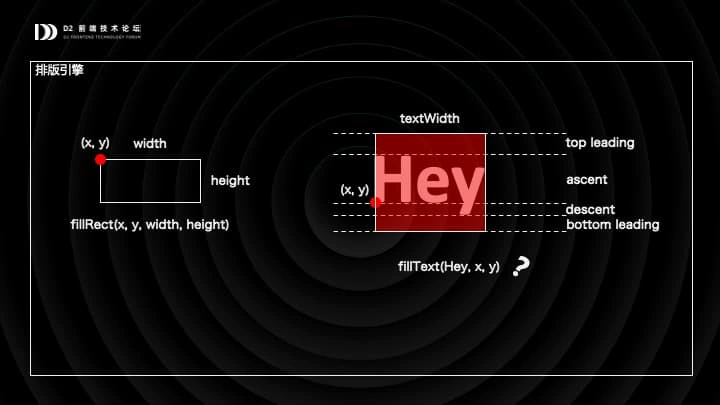
首先我们看一些基础知识。我们在 Canvas 中去画形状,比如画一个矩形的时候,是非常明确地知道,将要在哪一块区域绘制的,因为绘制的参数宽高就给出了答案。但是绘制文本的时候,你必须通过一些手段才能知道这些信息。通过对文本的测量,你才能知道文本你绘制的原点在哪,文本占据的怎样一块区域。
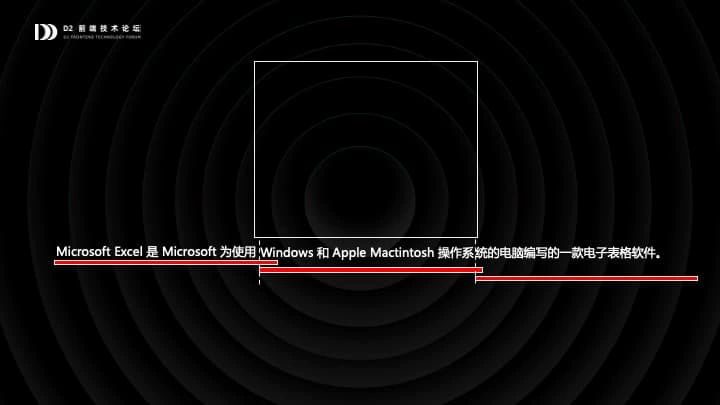
有了这些知识,就可以进行排版了。假设我们现在要把这么一段文本排进上面这个单元格,首先根据单元格的宽度去把文本拆成若干行。这里是有分词的,第二行开头,Windows 的前几个字母可以排进第一行的,但是因为整个单词排不进去,就会被划到第二行。
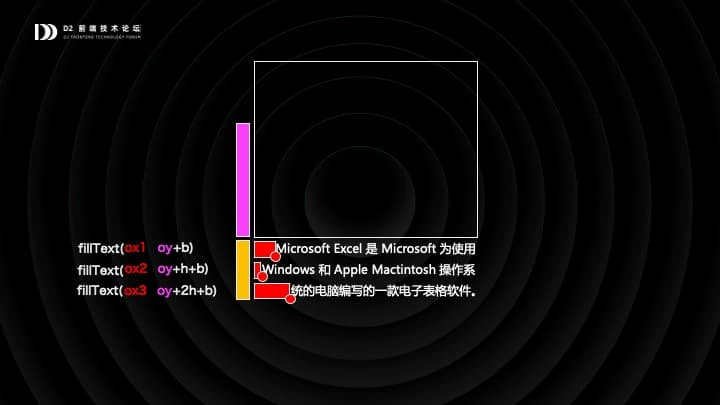
拆成三行之后,会根据水平对齐和垂直对齐,比如图里的水平对齐是靠右对齐,垂直对齐是底部对齐,根据对齐方式测量出每一行文本的原点,原点的坐标就传给 fillText 方法来绘制了。

这就是整个排版和绘制的原理。这样,我的第三个故事,也就讲完了。总结一下:
- 选择 canvas 渲染表格主界面。
- 分层的表格渲染管线,减少重绘。
- 双缓冲画布支持流畅滚动。
- 自研小型排版引擎,支持单元格内折行、分词、对齐等样式。
这样,三个故事就全部讲完了。其实说了这么多,钉钉表格,从 0 到 1 的研发,究竟走了一条怎样的路呢?其实也很简单:
- 向上,吸收和借鉴桌面软件的已有成熟设计,比如 RangeMan,渲染管线的思想,分词和排版算法。
- 向下,整合前端领域最先进,最主流的技术,包括 WebAssembly,Worker,Canvas 等等。
把它们聚合在一起,共冶一炉,锻造出钉钉表格这样一个超级复杂的 Web 应用。
我的分享就到这里,再次感谢 D2 组委会。